记录配置过程中踩的坑,GPU 节点的系统为 Ubuntu 24.04。
显卡驱动安装
根据 文档 指引,首先需要安装配置好显卡驱动
驱动安装
跟随 指引,首先确保设备上有 NVIDIA 显卡,并且被正确识别
lspci | grep NV
10:00.0 VGA compatible controller: NVIDIA Corporation GA102 [GeForce RTX 3070 Ti] (rev a1)
10:00.1 Audio device: NVIDIA Corporation GA102 High Definition Audio Controller (rev a1)并安装了 gcc 编译器
gcc --version接着根据自身情况选择需要的安装方式,这里采用的是 Network Repository Installation.。先配置仓库
wget https://developer.download.nvidia.com/compute/cuda/repos/<distro>/<arch>/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt update安装 CUDA 和驱动,并重启
sudo apt install cuda-toolkit cuda-drivers
sudo reboot
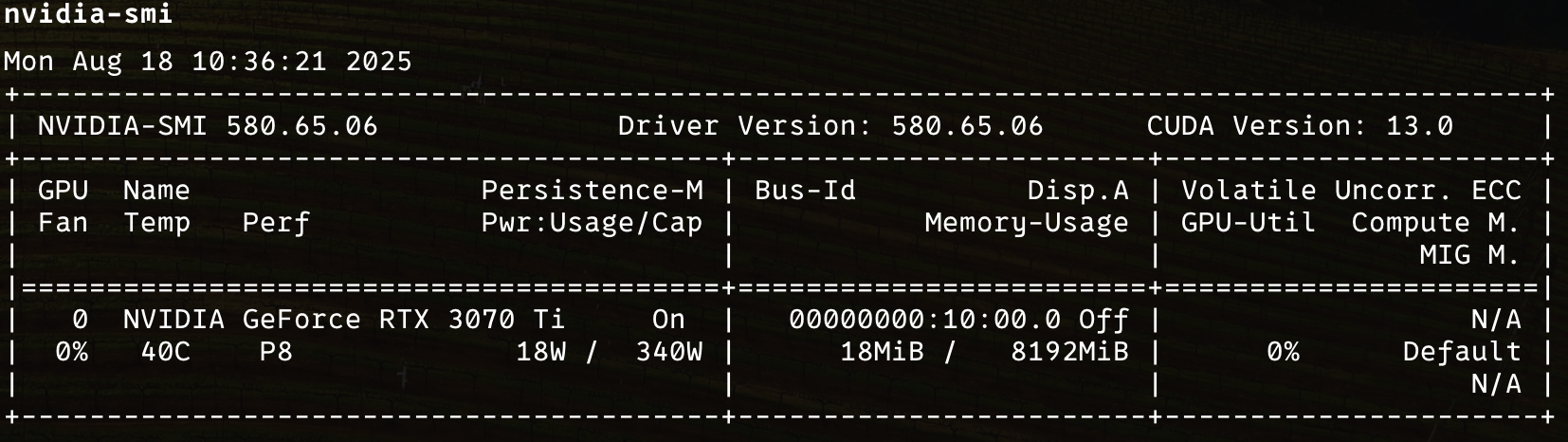
执行 nvidia-smi 判断驱动是否安装识别成功,并查看 CUDA 版本
安装 NVIDIA Container Toolkit
参考 文档
配置远程仓库并更新
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get update安装 Toolkit 组件
注意
1.17.8-1并不是最新版,可以移除=${NVIDIA_CONTAINER_TOOLKIT_VERSION}直接安装最新版。
export NVIDIA_CONTAINER_TOOLKIT_VERSION=1.17.8-1
sudo apt-get install -y \
nvidia-container-toolkit=${NVIDIA_CONTAINER_TOOLKIT_VERSION} \
nvidia-container-toolkit-base=${NVIDIA_CONTAINER_TOOLKIT_VERSION} \
libnvidia-container-tools=${NVIDIA_CONTAINER_TOOLKIT_VERSION} \
libnvidia-container1=${NVIDIA_CONTAINER_TOOLKIT_VERSION}同时还需要安装 nvidia-container-runtime
sudo apt install -y nvidia-container-runtimeK3S 配置
按前序步骤安装完成后,重启 k3s 服务即可
sudo systemctl restart k3s
// agent 请使用以下命令
sudo systemctl restart k3s-agent
根据 k3s 文档,k3s 会自动识别 nvidia-container-runtime 并在集群中创建 RuntimeClass 对象。重启后检查容器引擎的配置,如果有以下内容则说明识别成功。
sudo grep nvidia /var/lib/rancher/k3s/agent/etc/containerd/config.toml
[sudo] password for trganda:
[plugins.'io.containerd.cri.v1.runtime'.containerd.runtimes.'nvidia']
[plugins.'io.containerd.cri.v1.runtime'.containerd.runtimes.'nvidia'.options]
BinaryName = "/usr/bin/nvidia-container-runtime"安装 Device-plugin
https://github.com/NVIDIA/k8s-device-plugin#deployment-via-helm
最后在集群中安装 nvidia-device-plugin,添加仓库并更新
helm repo add nvdp https://nvidia.github.io/k8s-device-plugin
helm repo update执行安装命令
helm upgrade -i nvdp nvdp/nvidia-device-plugin \
--namespace nvidia-device-plugin \
--set runtimeClassName=nvidia \
--set affinity=null \
--version 0.17.1Info
注意这里的
--set runtimeClassName=nvidia和--set affinity=null配置,前者表示创建的 pod 需要配置runtimeClassName=nvidia这样才能识别并使用 NVIDIA GPU 资源,这一点在 k3s 文档 中有进行说明;后者表示关闭亲和配置,否则会导致调度识别从而导致 POD 无法创建。
最后测试一下,注意这里也添加了 runtimeClassName: nvidia,k3s 默认使用的 runtime 是 runc,使用 nvidia 需要显示配置。
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
restartPolicy: Never
runtimeClassName: nvidia
containers:
- name: cuda-container
image: nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda12.5.0
resources:
limits:
nvidia.com/gpu: 1 # requesting 1 GPU
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
EOF
若成功运行并有如下日志则说明成功了
kubectl logs gpu-pod
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done